さて、前回の続きです。
前回はエクセル形式でデータを保存するところまでコードを書いた。
でも、会社名と電話番号がまだ足りない。
電話番号の取得は結構めんどくさそうなので、まずは、
会社紹介のページから会社名を取得する方法を記述する。
参考にしたサイトはこちら。とても分かりやすかったです。感謝!!!
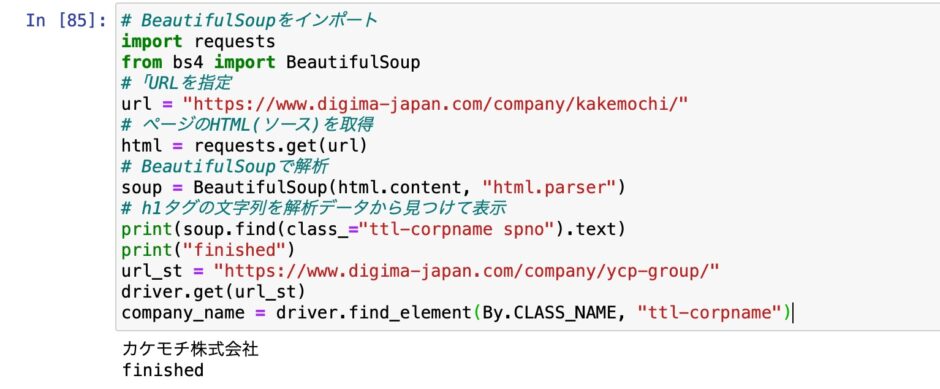
今回のコードの全容
# BeautifulSoupをインポート
import requests
from bs4 import BeautifulSoup
# URLを指定
url = "https://www.digima-japan.com/company/kakemochi/"
# ページのHTML(ソース)を取得
html = requests.get(url)
# BeautifulSoupで解析
soup = BeautifulSoup(html.content, "html.parser")
# h1タグの文字列を解析データから見つけて表示
print(soup.find(class_="ttl-corpname spno").text)
print("finished")beautifulsoup
beautifulsoupを使うにはmacの場合、ターミナルからインストールする必要がある。
pip3 install beautifulsoup4beautifulsoupで出来ること一覧はこちらのサイトが分かりやすい。
html = requests.get(url)このコードでHTMLを取得した後、beautifulsoupで解析し、
タグで要素を抽出できる。
抽出例
items = soup.find_all("item")itemの下に何かある。例えば、item以下にあるtitleなどのタグを取得したい!時はこれ、
for item in items:
print (item.title)
print (item.description)
print (item.date)中身だけ取り出す時はstringをつける。
for item in items:
print (item.title.string)
print (item.description.string)
print (item.date.string)HTMLを見やすくするコードはこちら、
print(soup.prettify())soup.find(class_=”ttl-corpname spno”).text)
ここで、class=ではなくclass_=であることに注意!!!
結果
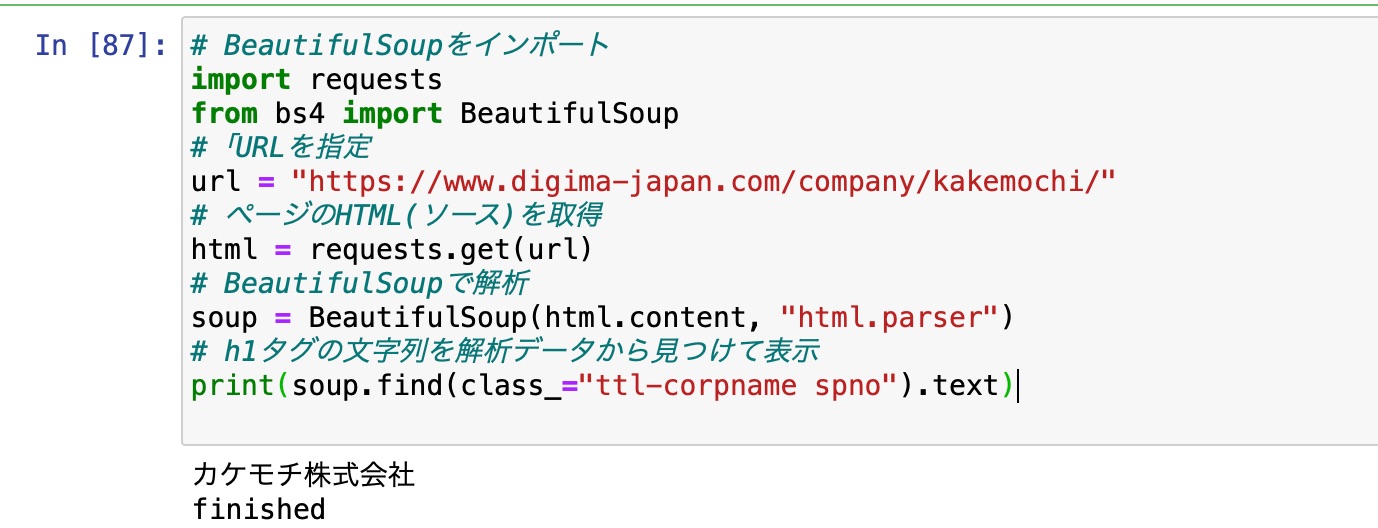
ちゃんと会社名が取得できました。
まとめ
beautifulsoupを使ってHTMLを解析し、会社名を取得することができた。
seleniumはWEBページの動作テスト用で作業を自動化することができる。
beautifulsoupはseleniumでWEBページが遷移した後にHTMLを解析して、文字列を取得できる。
次回は今回の処理をループで回し、会社毎のデータと結合したいと思う。
最後まで読んでいただきまして、有難うございました。
毎日コツコツ、お互いに頑張りましょう!