実践的な問題をやってみたくて、ランサーズに掲載されていた案件を解いてみた備忘録です。
実際の案件についてプログラミングをすれば、実社会で役に立つ技術が習得できるよね^^
今回はエクセルへの出力は省略し、また別の機会で投稿します。
実際の案件の内容
案件は下記の通り、
“””
下記条件の企業のリスト化をお願いいたします。
流れとしては下記の通りです。
企業をサイトで検索→エクセルに入力
※企業名、代表氏名、住所、電話番号、URLの順番でエクセルに入力(日本語)
単価:10円/件
件数:640件
金額:640件×10円=6,400円(ランサーズ手数料を含む)+消費税
期限:5/15
こちらのURLでhttps://www.digima-japan.com/company/
※1 企業名表記に関して、下記の表記で統一お願いいたします。
働きマン(株)← ✕
働きマン株式会社← ◯(株式会社と名前の間はスペース無し)
※2 重複企業はすべてリスト化せずに、どれか1つをリスト化していただければ問題ありません。
(〇〇株式会社△△支店と記載があるので、リスト化の際は〇〇株式会社の部分だけエクセルに入力していただければ幸いです。)
※3個人名義で登録されている企業(田中太郎など)はリスト化対象企業から除外
“””
コードを書く
ライブラリのインポート
必要なライブラリをインポートする。
正直、最初から全部をキレイに宣言してそろえることは難しいけど、慣れてくると同じメソッドを使い回すので、できるようになると思う。
from selenium import webdriver
from time import sleep
import pandas as pd
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECseleniumを使って、webページを操作する。いろんな命令が準備されているので、便利だ。もともとは、スクレイピング用ではなく、webページのテスト用のツールとのこと。
pandasもインポートする。データを取得、加工する際に便利。
timeもインポートする。webページが表示されるまで待機させるのにタイマーとして使ったりする。
timeよりもよりwebページの動作に対して柔軟に制御できるのがWebDriverWaitになる。これはあるオブジェクトが表示されるまで待たせる、とか、クリックできるようになるまで待たせる、とか、時間で区切って待たせる、というよりもより使い勝手がいい。無駄に長い時間待機させることがなくなるしね。
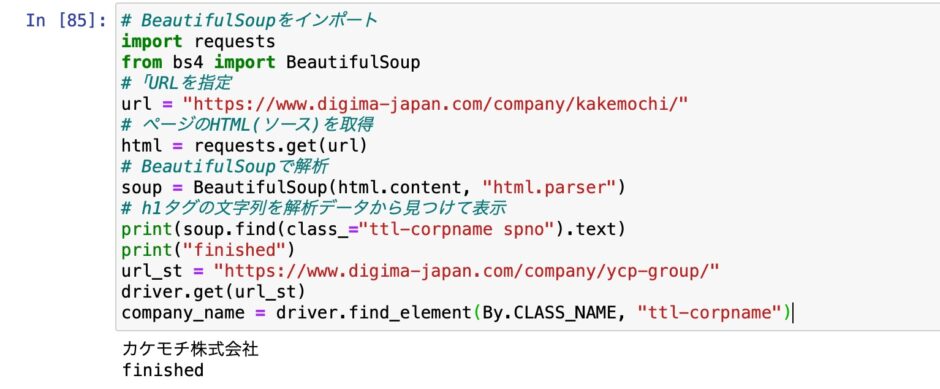
urlから対象のwebページを開く
#GoogleChromeを起動
driver = webdriver.Chrome()
driver.implicitly_wait(3) # 3秒待て
# サイトへアクセス
url_st = "https://www.digima-japan.com/company/"
driver.get(url_st)
time.sleep(3) # 3秒待てまずはGoogle Chromeを開く。開いてから、3秒待つ。正確には、開け!と命令してから、3秒待たせる。
(Google ChromeはHTMLを確認しやすいので、スクレイピングのコードを書く時にはよく使われている。)
url_stという変数を用意して、その中にurlを文字列として代入する。
driver.get(url_st)は()内のurlを得なさい。(表示しなさい)という意味。
そして、3秒待たせる。これも、ポンポンと次の命令をすると、ブラウザの処理が追いつかなくて、エラーが発生するから、仕方ない処理。
企業の詳細情報のページへジャンプする
wait = WebDriverWait(driver, 20) # 最大20秒
elems = wait.until( EC.visibility_of_all_elements_located( (By.LINK_TEXT,"詳しく見る")) )
# "詳しく見る"テキストを含むリンクを見つけるまで、待て。
# そして、見つけたら、リンクを取り出して、リストにしろ。
# リスト名はelems
urls = [] # 空のリストを用意
for elem in elems:
urls.append(elem.get_attribute("href")) # WebDriverElementから"href"だけ抽出してリスト化
# https://teratail.com/questions/33026wait =, elems=の2行は、結構肝になるところ、
wait = WebDriverWait(driver, 20) # 最大20秒
elems = wait.until( EC.visibility_of_all_elements_located( (By.LINK_TEXT,"詳しく見る")) ) Chromeの検証の機能から操作したいページのHTMLを表示して、クリックしたい対象を探す。
そのボタンの特徴的なもの、例えば、classname, id, testがあればそれらを元に検索をして、そのボタンを見つけ出すことができる。ここでは、(By.LINK_TEXT,”詳しく見る“)のところがそれにあたる。
上記の(By.LINK_TEXT,”詳しく見る“)がvisibility(見えるように)になったら、次の処理となる。
「見えるようになった」というイベントまで、wait(待て)を実行する。
条件が揃うまで、待ったら、見つけた(By.LINK_TEXT,"詳しく見る")にあたる物をelemsと定義されたリストに登録しろ。
空のリストに企業の詳細情報のurlを追加保存していく
ここも、ちょっと手こずった。
.get_attribute(“href”)がミソになる。
urls = [] # 空のリストを用意
for elem in elems:
urls.append(elem.get_attribute("href")) # WebDriverElementから"href"だけ抽出してリスト化上記のelemsはtype(elems)は確認すると、リスト型のデータであることがわかる。
そこで、urlを一つずつ取り出すためにurl=elem[0]と引数を指定して、これをdriver.get(url)としても、エラーになる。
リストelemsには文字列"https://www.digima-japan.com/company/"のような形式では保存されておらず、WebDriver用のいろんな付属情報が一緒に保存されている。
そこで、.get_attribute(“href”)で要素elems[0](上のコードではelemsから取り出した要素を変数elemに代入している)の中から、さらにリンクの参照情報”href”のattribute(属性)をget(得る)する。
この技を教えてくれたのは、こちらのサイトです。ありがたや〜。めちゃくちゃ助かりました!!感謝しています!!
getした情報"https://www.digima-japan.com/company/"のような文字列をリストurlsに.append()で追加保存していく。今度はリストurlsの要素を取り出せば、その値はdriver.get(url)のurl部分にそのまま代入できる。
企業情報を取得し、表示する
for url in urls: # urlsリストから一つずつurlを取り出してページを開く
time.sleep(3)
driver.get(url)
time.sleep(3)
# テーブルデータをDataFrameにて取得する
cul_url = driver.current_url
data = pd.read_html(cul_url, header = 0)
print(data[3]) # 3秒待て
print()
driver.back() # 一つ前のページに戻る
#最初のページに戻る
driver.get(url_st)cul_urlには現在のページのurlが入っている。ちょっと、周りくどいかなぁ。3行目で使っているdriver.get(url)のurlを用いても良いと思う。
import pandas as pdでインポートしたpandasが登場!pd.read_html(cul_url, hedder =0)でdataの中に表データがごそっと保存される。各表データごとに分けられて、引数を使ってその表を取り出すことができる。例えば、data[0]みたいな感じ。
調査対象の表はdata[3]で取り出すことができた。
1ページ分取り出すために、リストurlsの中にある要素の数だけループする。
取り出した表をプリントすると、こんな感じになった。

1ページ分取り出したら、最初のスタートページに戻る。driver.get(url_st)
開発環境
jupyter notebook
python3
エラー発生の話
通常、クリックしたいボタンを特定できたら、.click()とすると、マウスでクリックした操作と同じ命令を実行できて、次のイベントが発生するのだけれど、今回は単純には行かなかった。
browser_from = driver.find_element(By.CLASS_NAME,"bit__clickablemap_map_kantou")
time.sleep(3)
browser_from.click()通常は、上記のような感じで、.click()とするとページが遷移する。
でも、今回のwebページでは複数の同じように表示されたボタンがあり、同じクラス名class=”company-link__button company-link__detail“が複数あったため、エラーが発生した。(そりゃそうだ)
そこで、<a>タグの属性hrefを検索の対象として、リンク先のリストを作り、その要素(url)を元にdriver.get(url)が使えるように一手間かけなければならなかった。
まとめ
今回はとりあえず、必要な情報を1ページ分だけ取得するコードを書いたのですが、
実際は64ページあるので、64ページ分をループさせる必要があります。
また、エクセルにデータを書き込むコードもまだ紹介できていないので、
これらのコードについては、今後投稿してきたいと思います。
最後までお読みいただき、ありがとうございました。ご質問などございましたら、私の勉強にもなりますので、コメントいただけますと幸いです。
それでは、明日も頑張って勉強していきましょう!
そうだ!コードを通しで貼り付けておきますね^^
from selenium import webdriver
from time import sleep
import pandas as pd
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
#
#GoogleChromeを起動
driver = webdriver.Chrome()
driver.implicitly_wait(3) # 3秒待て
# サイトへアクセス
url_st = "https://www.digima-japan.com/company/"
driver.get(url_st)
time.sleep(3) # 3秒待て
wait = WebDriverWait(driver, 20) # 最大20秒
elems = wait.until( EC.visibility_of_all_elements_located( (By.LINK_TEXT,"詳しく見る")) ) # "詳しく見る"テキストを含むリンクを見つけるまで、待て。
# そして、見つけたら、リンクを取り出して、リストにしろ。
# リスト名はelems
urls = [] # 空のリストを用意
for elem in elems:
urls.append(elem.get_attribute("href")) # WebDriverElementから"href"だけ抽出してリスト化
# https://teratail.com/questions/33026
for url in urls: # urlsリストから一つずつurlを取り出してページを開く
driver.get(url)
time.sleep(3)
# テーブルデータをDataFrameにて取得する
cul_url = driver.current_url
data = pd.read_html(cul_url, header = 0)
print(data[3]) # 3秒待て
print()
driver.back()
time.sleep(3) # 3秒待て
#最初のページに戻る
driver.get(url_st)