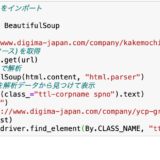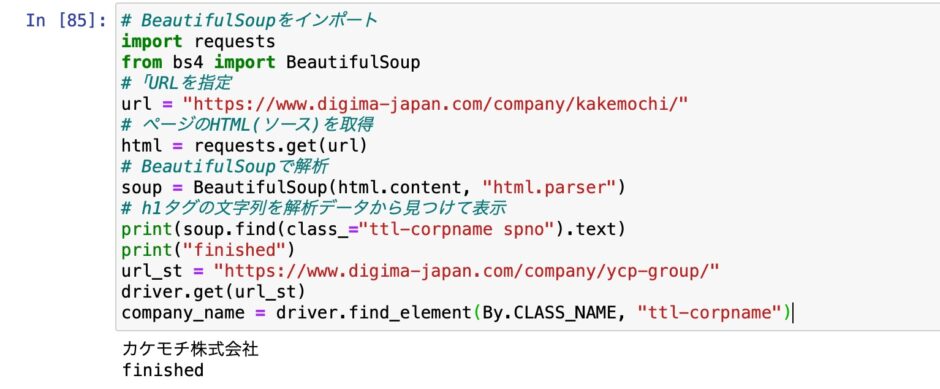
前回はスクレイピングのコードをざっくりと書いた。
今回は取得したデータを整理する方法についての備忘録を作ろうと思う。
pandasで取得したデータは次のようになっている。
従業員数 250 1 URL http://ycp.com/ja/ 2 事業内容 ・海外展開支援 ・海外調査 ・経営人材派遣 ・経営コンサルティング ・ファイナンシャルアドバ... 3 主要取引先 非公開 4 資本金 USD500,000 5 設立年月日 2011年8月 6 所在地 【東京オフィス】東京都港区南青山1-1-1 新青山ビル東館10F 7 海外拠点情報
これをエクセルのデータ、(著者はmacを使っているので本当はnumbersのデータですが、便宜上、エクセルと呼びます。データを読み書きするためのコードはnumbersもエクセルも同じ)にしたいと思う。
スクレイピングして得られたデータの確認

現在のデータは
従業員数、URL、事業内容、主要取引先、資本金、設立年月日、所在地、海外拠点情報、のデータが、それぞれ1行ずつ書かれている。
これを次のようなテーブルに作り直したい。(この表を表1と呼ぶことにする。)
| 企業名 | 代表氏名 | 住所 | 電話番号 | URL | 備考 |
| aa株式会社 | 石田裕樹 | 東京都港区南青山1-1-1 新青山ビル東館10F | 1234567890 | http://ycp.com/ja/ | |
| bb株式会社 | bbbb | bbbb | 0123456789 | bbbb | |
| 株式会社cc | cccc | cccc | 9012345678 | cccc |
現在のデータには会社名と電話番号の記載がないので、後でなんとかしなくちゃ。
各社のデータを一つの表にまとめる()
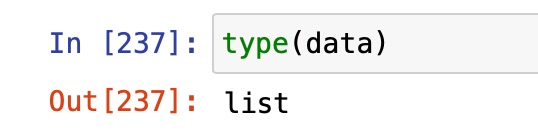
まずはtype()でデータの型を確認するとdataという変数はlist型であることが分かる。
また、type(data[3])を調べると、

pandas.core.frame.DataFrame
と表示される。(ちなみに、このような情報から、やりたいデータ処理の仕方をググると大抵お目当てのコードが取得できる。)
DataFrameの操作をまとめた記事があったので、リンクをメモしておこう。ありがたや〜
前投稿のfor文に、data_listというリスト型の変数を定義して、その中にdata[3]に入っている会社情報を.append()を使って追加していく。
data_list=[] # 空のリストを用意して、data[3]の内容を代入する
for url in urls: # urlsリストから一つずつurlを取り出してページを開く
driver.get(url)
time.sleep(3)
# テーブルデータをDataFrameにて取得する
cul_url = driver.current_url
data = pd.read_html(cul_url, header = 0)
data_list.append(data[3]) # data_listにdata[3]の内容を代入する
print(data[3]) # 3秒待て
print()
driver.back()
time.sleep(3) # 3秒待て
#
driver.get(url_st)結果

ズラ〜っとデータが並ぶ、でもこれじゃあ、ちょっと将来的に扱いにくい。出力したい形式には遠いなあ。
各会社について情報を取得するループを回す前に、データを並べ替えたほうが良さそうだ。
データの並べ替え
項目を取得する
現在、行(row)の先頭に”代表者氏名”や”住所”などの項目があるけど、これを表1のように列(colum)の一番上に代表者氏名や住所の項目を配置して、行ごとにその会社の情報を記述するように並べ替えたい。
そこで当初は、行列の各要素を取得して、並べ替えることを考えた。
が、しかし、pythonにはpandasの中に.transpose()というものがある。
これを使うと、一瞬で行列を入れ替えてくれる。すげ〜
import pandas as pd
df.transpose()結果
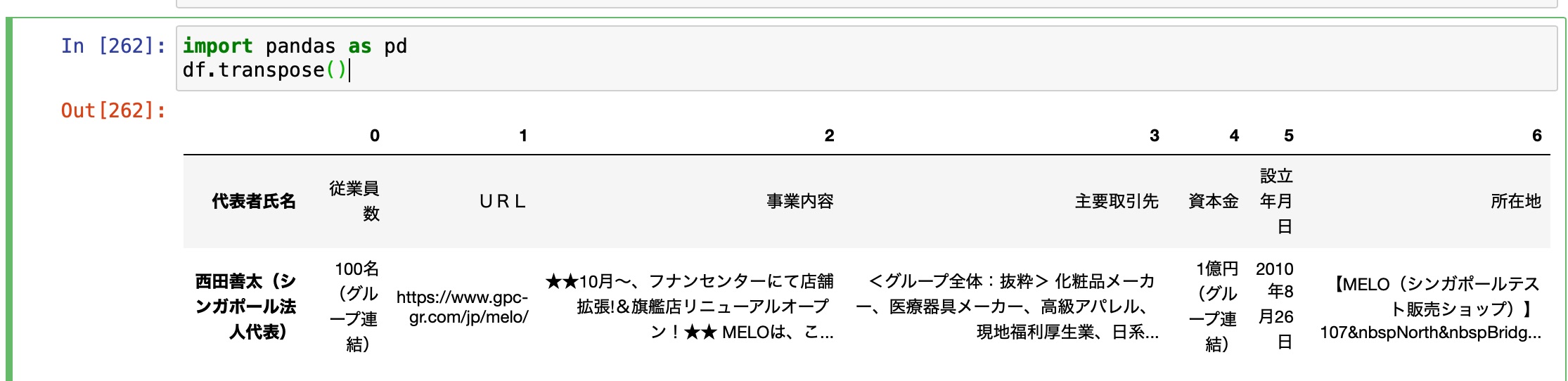
よしよし^^
たった1行のコードで出来ちゃうなんて!
不要な列の削除
.drop()で不要な列を削除する。
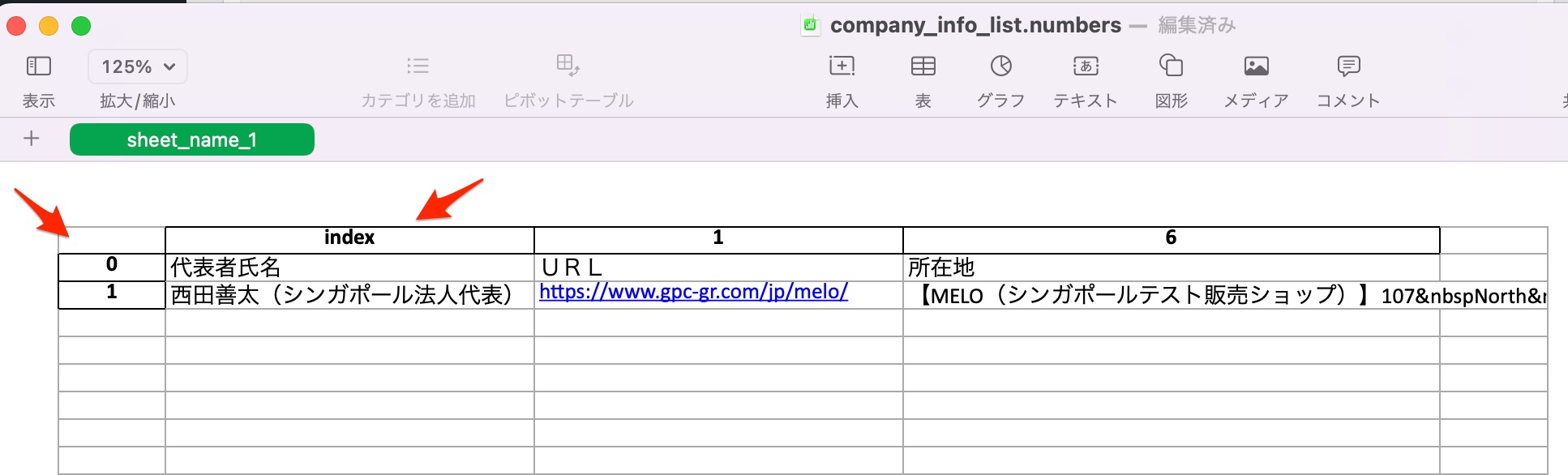
上の表で列の上に0から6の数字が並んでいる。これが列の名前になる。
不要な列、0, 2, 3, 4, 5を指定して、削除する。
_df.drop([0,2,3,4,5], axis=1, inplace=True)結果

必要な列(column)だけ残りました。
列の名前(列名)を変更する
列の名前を”代表者氏名”、”URL”、”所在地”に変更する。
一つ上の_df.drop()の結果を見ると、代表者氏名のところに列名の設定がない。
これは”代表者氏名”が書かれている列がindexになっている為と思われる。
そこで、dataframeにindexを追加してやる。
準備 indexを新たに追加する
indexを追加するには、
_df.reset_index(inplace=True)を使う。ここのinplace=Trueは元のデータを書き換えるの意味。
さて、indexも各列に準備できたので、いよいよ列名を変更する。

列名には1行目に入っている要素を使いたい。そんな時にはこんなコードを書くと実現できる。
headers = _df.iloc[0] new_df = pd.DataFrame(_df.values[1:], columns=headers)
1行目のコードでインデックス番号0の行をheaders(列名)にするといっている。
2行目のコードでは_df.values[1:]でvaluesのデータをスライスしてインデックス番号1のvaluesから使えとしている。
結果

列の追加、並び替え
”企業名”と”電話番号”と”備考”の列がないので追加して、列を並べ替える作業をしたいが、この記事が長くなりすぎるので、また今度の投稿にする。
エクセルへの出力
エクセルへdataframeを出力する(Excelファイル(拡張子: .xlsx, .xls)として書き出す(保存する))には下記のコードで実現できる。
まずはライブラリをターミナル(mac)からインストールする
$ pip install openpyxl
$ pip install xlwt_df.to_excel('/Users/user_name/IT blog/company_info_list.xlsx', sheet_name='sheet_name_1').to_excel()で実現できる。引数に保存先のパス、シートの名前を指定する。
結果
筆者の開発環境はmacなので厳密にはexcelではないけれど、指定したフォルダにはちゃんと拡張子が.xlsxのファイルができていました。
まとめ
リスト型のデータについて各要素をこれまで色々といじくり回して表やら、2次元配列やらを作っていたが、pandasには強力で便利な関数がたくさんある。
スクレイピング後のデータをクレンジングするのには勉強しておいて損はないと改めて思った。
次回は今回書ききれなかった列の追加、並べ替えについて書こう。
それでは、毎日コツコツ勉強!お互いに頑張りましょう!