会社で売上データが毎月2回メールで届く。
そのデータを使って、各企業毎に売上を合計してランキングを作って上司に報告した。
見積もり件数がグループ内で数万件あるので、手作業では無理〜、ということで、python3でコードを書いて対応することにした。
備忘録として、使ったコマンドと使い方を記録しておく。
コードは3つのステップに分けて作った。
ステップ1:エクセルファイルからCSVファイルへ変換
ステップ2:報告書の特定のシートの情報を結合
ステップ3:シートの情報を集計して、売上ランキングを作成
今回はステップ1について書く。
エクセルからcsvファイルへ変換する。その時にめちゃめちゃトラブった。
なんでだろう?と思っていると、企業名に”Co.,Ltd.” のようにコンマ”,”が含まれていると、csvはデータをコンマで区切ってデータを取得する。csvはコンマ・セパレーテッド・バリューの略なので、当然。しかし、最初は開いたデータが壊れた理由が分からなかった。このようなエラーを回避するために、DataFrameを使うと便利だ。
コードの書き始めはDataFrameを知らなかったので、コンマを文字列から削除して、半角スペースに置き換える作戦をとることにした。後からDataFrameでコードを書いたら、めちゃシンプルになった。
目的別の各コード
フォルダ内のファイルのリストを作る
file_dir = "/Users/username/business_data/"
file_list = os.listdir(file_dir)
file_list_in = [s for s in file_list if "Overview" in s]変数”file_dir”にフォルダのパスを代入する。
フォルダ内のファイルリストを作るには、os.listdir()を使う。
os.listdir()でフォルダ(ディレクトリ)内のファイルのリストを作る。変数”file_list”にリストが入る。
“file_list”というリストの中から特定のファイル名を持つファイルを抽出する。この場合は、”Overview”という文字列が含まれるファイルをリスト化する。
抽出した結果をfile_list_in”というリストに入れる。
エクセルのデータを読み込む
df = pd.read_excel(file_dir + file_name, header=1, sheet_name=Sheet__) pandasでExcelファイルをpandas.DataFrameとして読み込むには、pandas.read_excel()関数を使う。
pd.read_excel()を使ってエクセルファイルを開き、その結果をdfに入れる。ちなみに、dfの中みをprintすると、こんな感じ。
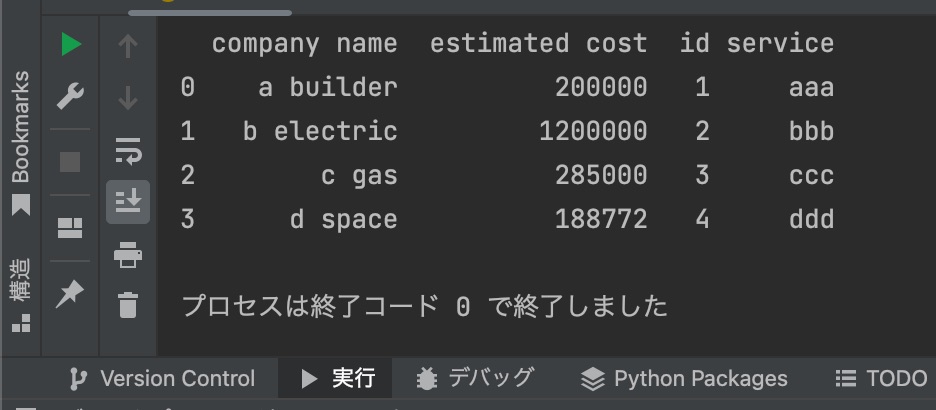
エクセルのsheetを指定して読み込み。変数"Sheet__"に代入した処理するシート番号をsheet_name=に渡すと、シートを指定できる。シート名、インデックス(0から始まる番号)どちらでもOK。
おまけ
DataFrameを使うと処理が楽だ。当初はデータを加工するのに2次元配列のリストを使って処理したが、DataFrameを使うと、コードが単純になる。
新しいフォルダを作る
保存先のフォルダ(ディレクトリ)を作る。exist_ok=Trueとすると、同じ名前のフォルダがあってもいい。os.mkdir()はこれが指定できないので、os.makedirs()の方が使い易い。
os.makedirs(new_dir_path_save, exist_ok = True)当初、os.mkdir()で保存先となる新しいフォルダを作る。でも、すでに存在していたら、エラーになるので、try:except:を使っていた。
エクセルファイルとしての保存
df.to_csv(new_dir_path_save + file_name_csv, columns=["company name", "estimated cost", "id", "project name", "service contents"], header=True, index=False)
インデックス(行の名前。デフォルトでは数字がゼロから割り振られる。)を無しでcsv形式にて保存するには、
index=False
を追記する。
保存するファイル名を加工
file_name_cut = file_name[:-4] # slice the file name from the last letter to delete "xlsx"
file_name_csv = file_name_cut + "csv" 拡張子"xlxs"の部分を削除するためファイル名の後ろから4文字スライスする。file_name[:-4]で加工できる。
スライスして拡張子がなくなった文字列に”csv”を追加して、新しく保存するファイル名を作り、file_name_csvへ代入する。
まとめ
今回は自分のメモ書きのため、内容がとっ散らかってしまったが、徐々にpythonのコーディング・テクニックをまとめていきたいと思う。