前回は beutifulsoupを使って、HTML内を解析し、必要な情報(会社名)を抽出する処理について記述した。
今回はその抽出した内容を各会社毎にDataFrameに追加する処理について記述する。
全体のコード
まずは今回改修した全体のコードを示す。
from selenium import webdriver
from time import sleep
import pandas as pd
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from IPython.display import display
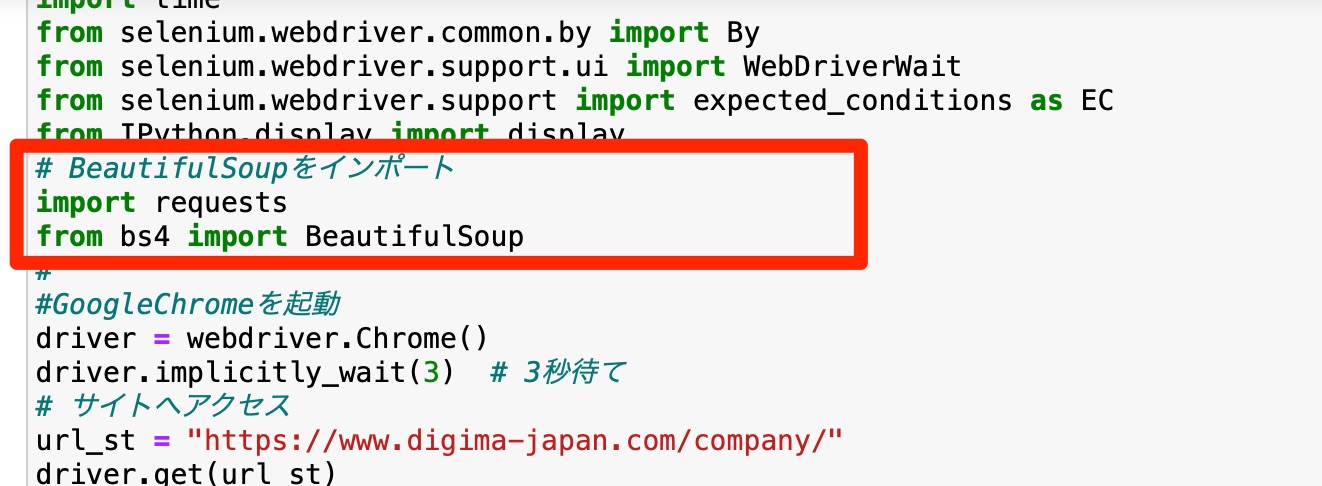
# BeautifulSoupをインポート
import requests
from bs4 import BeautifulSoup
#
#GoogleChromeを起動
driver = webdriver.Chrome()
driver.implicitly_wait(3) # 3秒待て
# サイトへアクセス
url_st = "https://www.digima-japan.com/company/"
driver.get(url_st)
time.sleep(3) # 3秒待て
wait = WebDriverWait(driver, 20) # 最大20秒
elems = wait.until( EC.visibility_of_all_elements_located( (By.LINK_TEXT,"詳しく見る")) ) # "詳しく見る"テキストを含むリンクを見つけるまで、待て。
# そして、見つけたら、リンクを取り出して、リストにしろ。
# リスト名はelems
urls = [] # 空のリストを用意
for elem in elems:
urls.append(elem.get_attribute("href")) # WebDriverElementから"href"だけ抽出してリスト化
# https://teratail.com/questions/33026
df_concat = pd.DataFrame() # 空のデータフレームを用意
for i in range(len(urls)): # urlsリストから一つずつurlを取り出してページを開く
url = urls[i]
driver.get(url)
time.sleep(3)
# ページのHTML(ソース)を取得
html = requests.get(url)
# BeautifulSoupで解析
soup = BeautifulSoup(html.content, "html.parser")
# h1タグの文字列を解析データから見つけてcompany_nameに代入
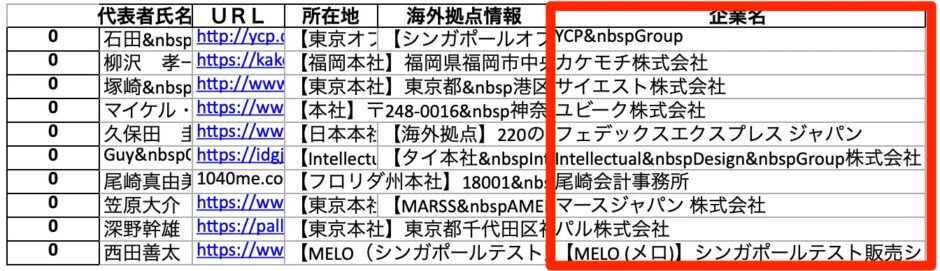
company_name = soup.find(class_="ttl-corpname spno").text
# テーブルデータをDataFrameにて取得する
cul_url = driver.current_url
data = pd.read_html(cul_url, header = 0)
# dataから引数3の要素を取り出す
df = data[3]
items = df.iloc[:, [0]]
data = df.iloc[:, [1]]
# 行列の入れ替え行を列に、列を行に変換
_df = df.transpose()
_df.reset_index(inplace=True)
# 不要な列を削除
_df.drop([0,2,3,4,5], axis=1, inplace=True)
# 行(引数)をheaders(列の名前)にする
headers = _df.iloc[0]
new_df = pd.DataFrame(_df.values[1:], columns=headers)
new_df["企業名"] = company_name
display(new_df)
# concatでDataFrameにデータを追加する。concatを使うと列名は追加されず、データ部分だけ追加してくれる。
# df_concatにnew_dfを追加する
df_concat = pd.concat([df_concat,new_df], axis=0)
print(url+"の処理が終わりました。")
driver.back() # webブラウザの「戻る」と同じ処理
time.sleep(3) # 3秒待て
#
driver.get(url_st)
print(df_concat)
df_concat.to_excel('/Users/username/Desktop/IT blog/company_info_list.xlsx', sheet_name='sheet_name_1')
print("処理が終わりました")処理結果
保存したエクセルデータを確認すると、企業名が追加されている。

変更点
BeautifulSoupとrequestsをimport
DataFrameに列を追加
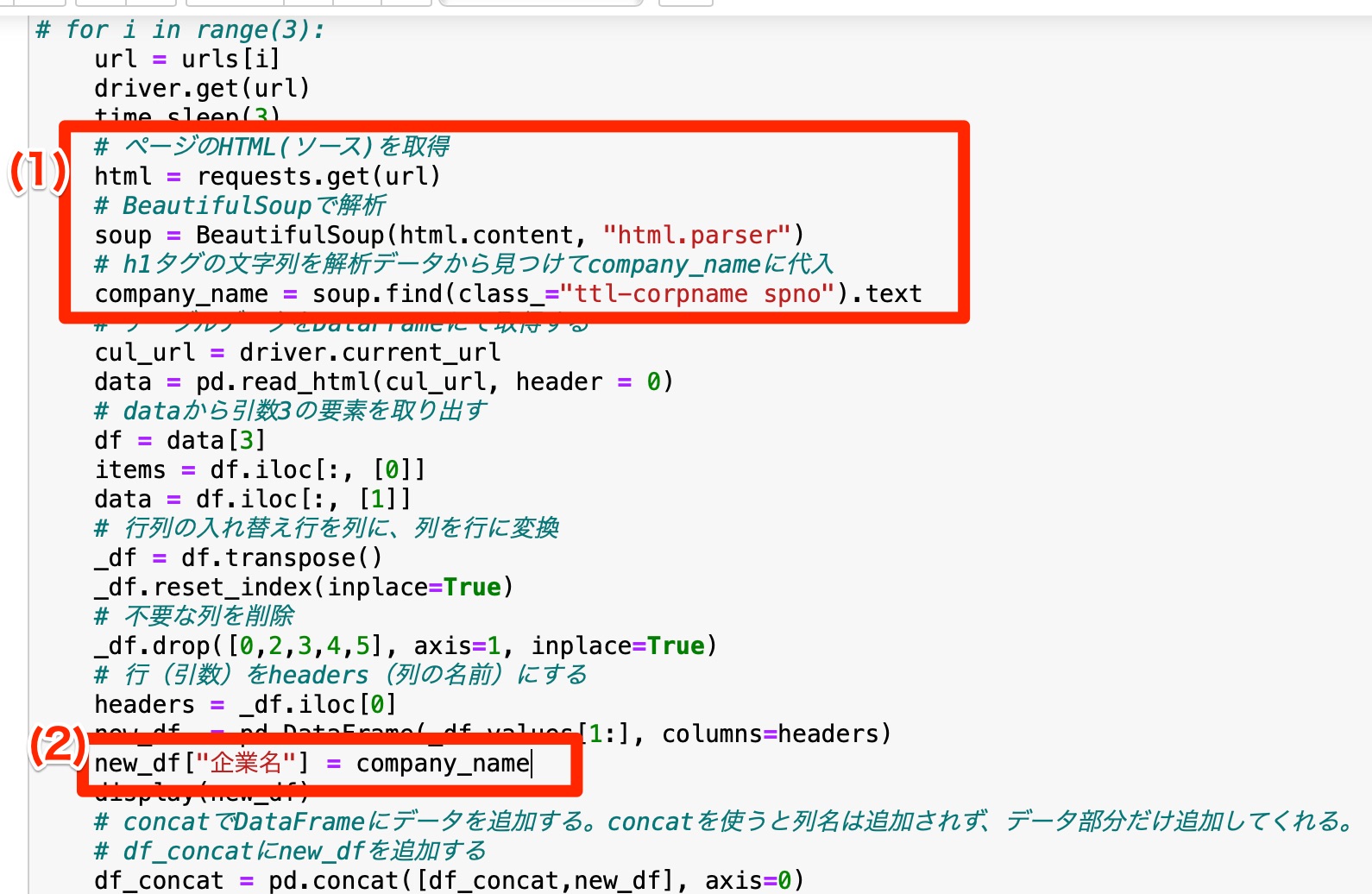
(1)request.get(url)
解析したいURLからHTMLデータを取得
(2)df[“列の名前”] = データ
DataFrameに新しい列を追加して、データを保存することができる。
まとめ
DataFrameに新しい列を追加する作業は結構頻繁に発生するので、使いこなせることは必須と思われる。